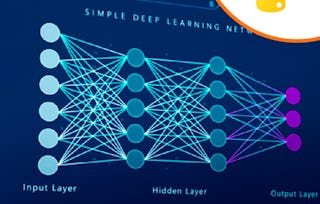
This course offers an in-depth, practical introduction to machine learning using Python, covering core concepts across supervised, unsupervised, and semi-supervised methods.
Through hands-on exercises, you will master key algorithms such as decision trees and random forests for classification, regression models for prediction, and K-means clustering to uncover patterns in unlabeled data. You will also learn how to implement model boosting techniques to enhance accuracy and apply strategies for effectively leveraging unlabeled data to improve performance. This course is designed for learners with a foundation in Python and basic statistics, making it ideal for aspiring data scientists, machine learning practitioners, and Python developers looking to deepen their skills. By the end of this course, You will be able to: - Explain and implement decision trees and random forests as classification algorithms. - Define and differentiate various types of machine learning algorithms. - Analyze the working of regression for predictive tasks. - Apply K-means clustering to explore and discover patterns in unlabeled data. - Use unlabeled data to improve model training. - Manipulate boosting algorithms to achieve higher model accuracy. Equip yourself with practical tools and advanced techniques to bring predictive power to your projects. Enroll now and advance your AI journey!